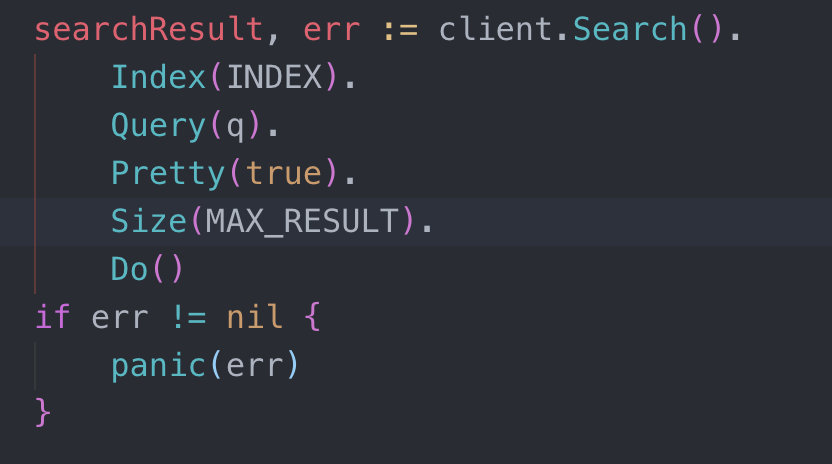
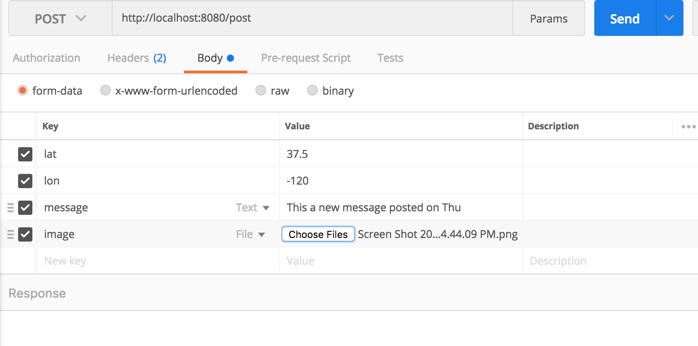
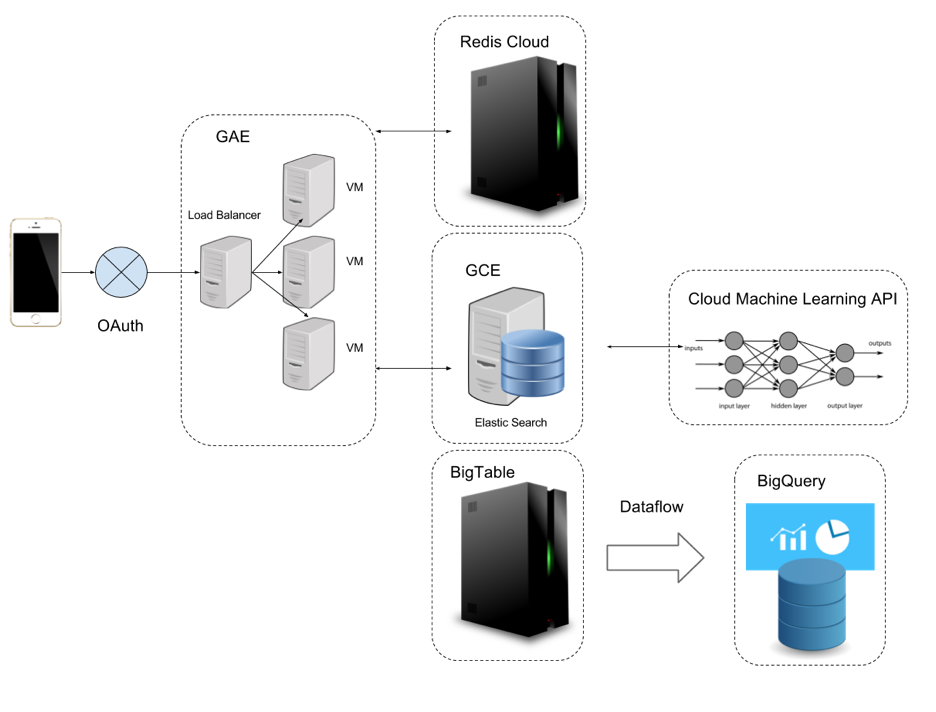
Logback
Description
Logback is a log module.

logger, appender, layout are tags of logback
Configuration
- Create a
logback.xmlinresourcespackage

- Defines some properties of the logback configuration.
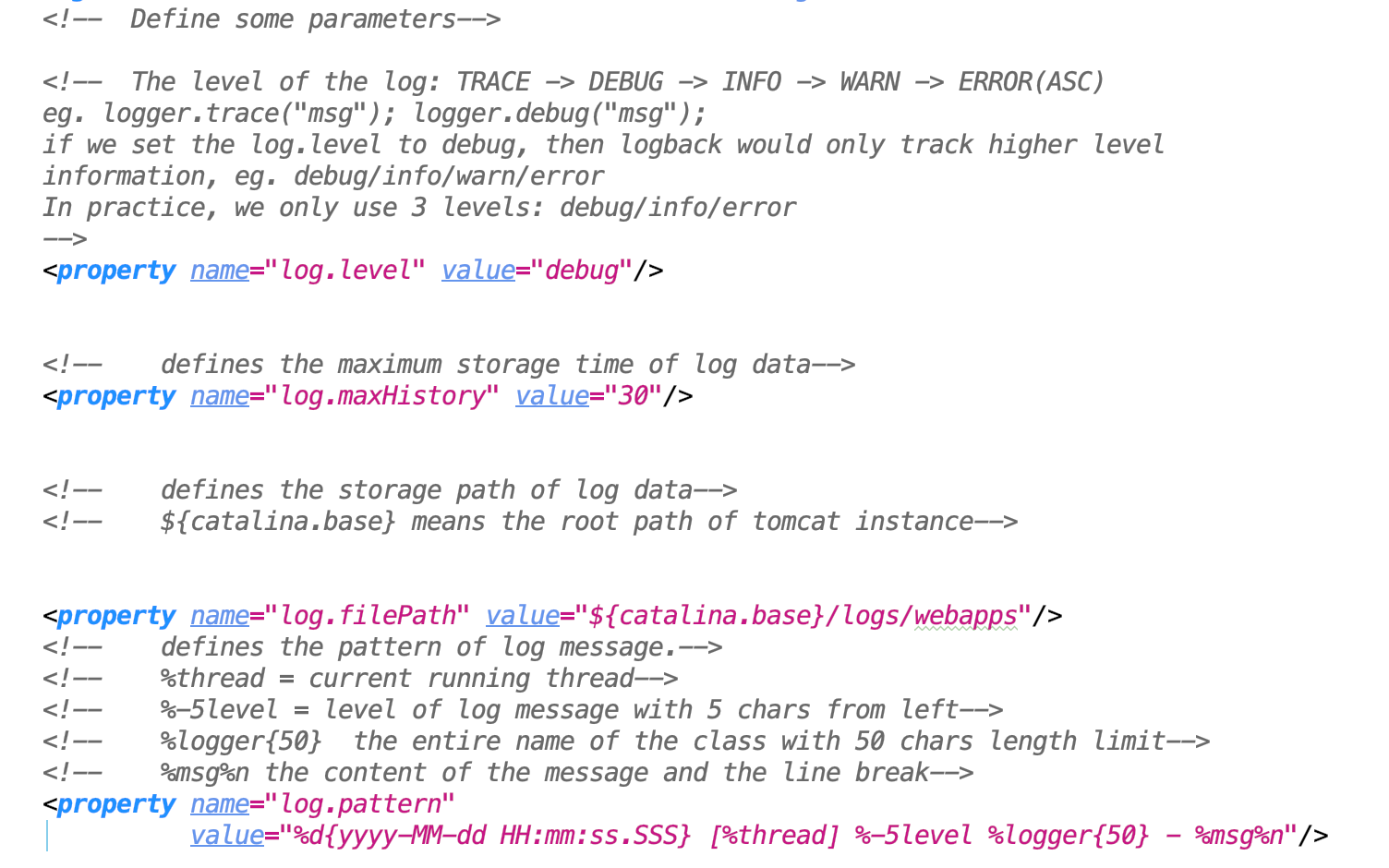
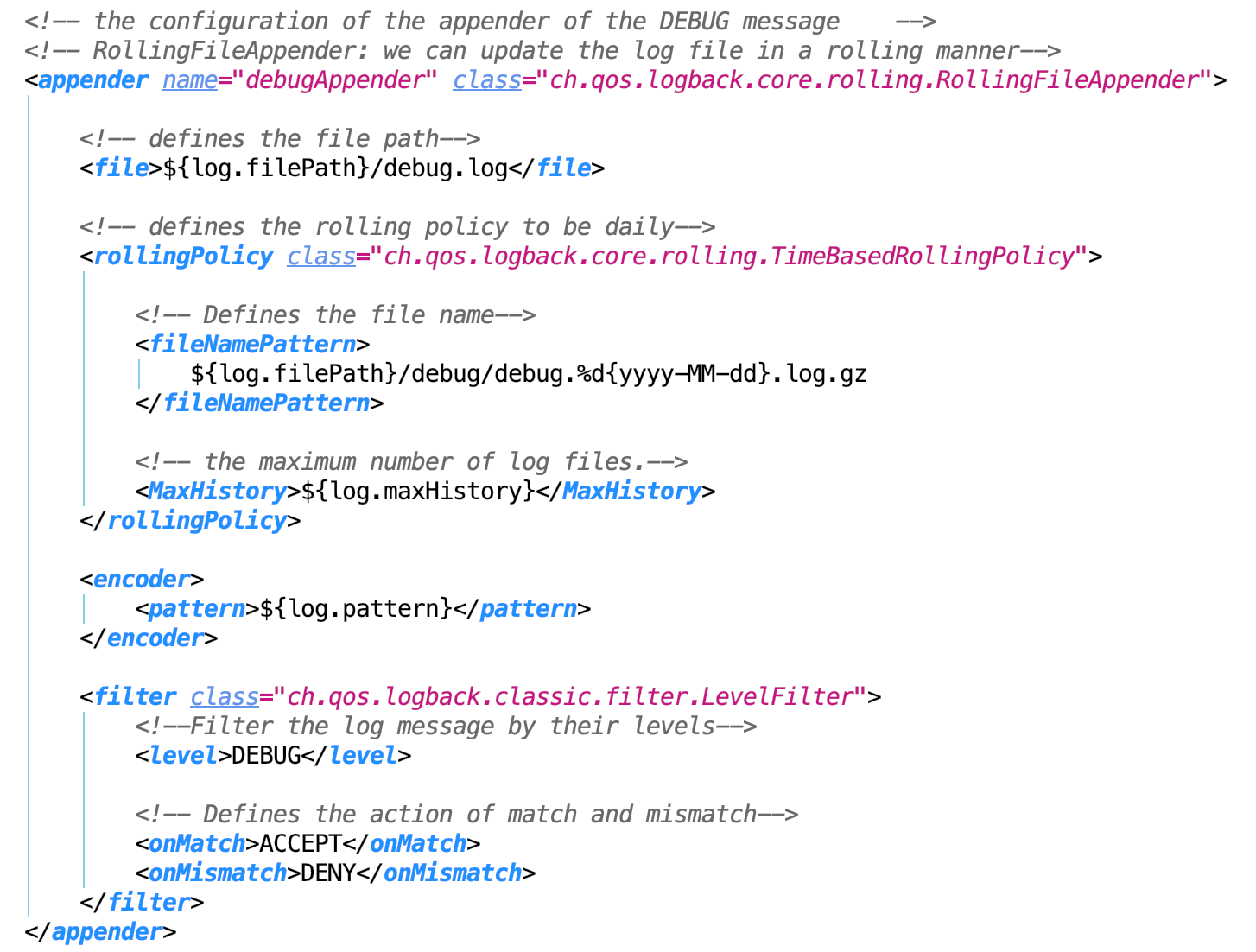
- Defines the appenders.

Info, Error is the same as Debug.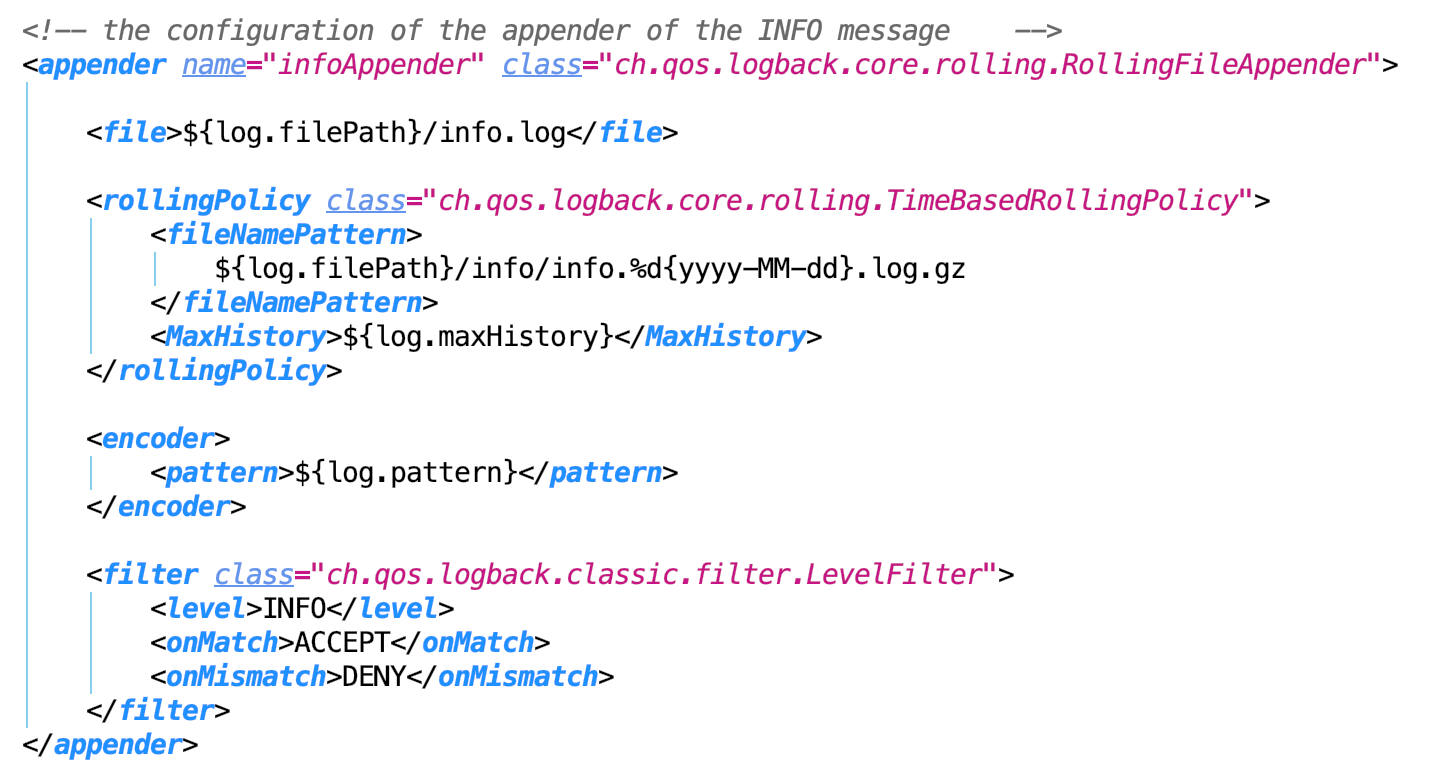
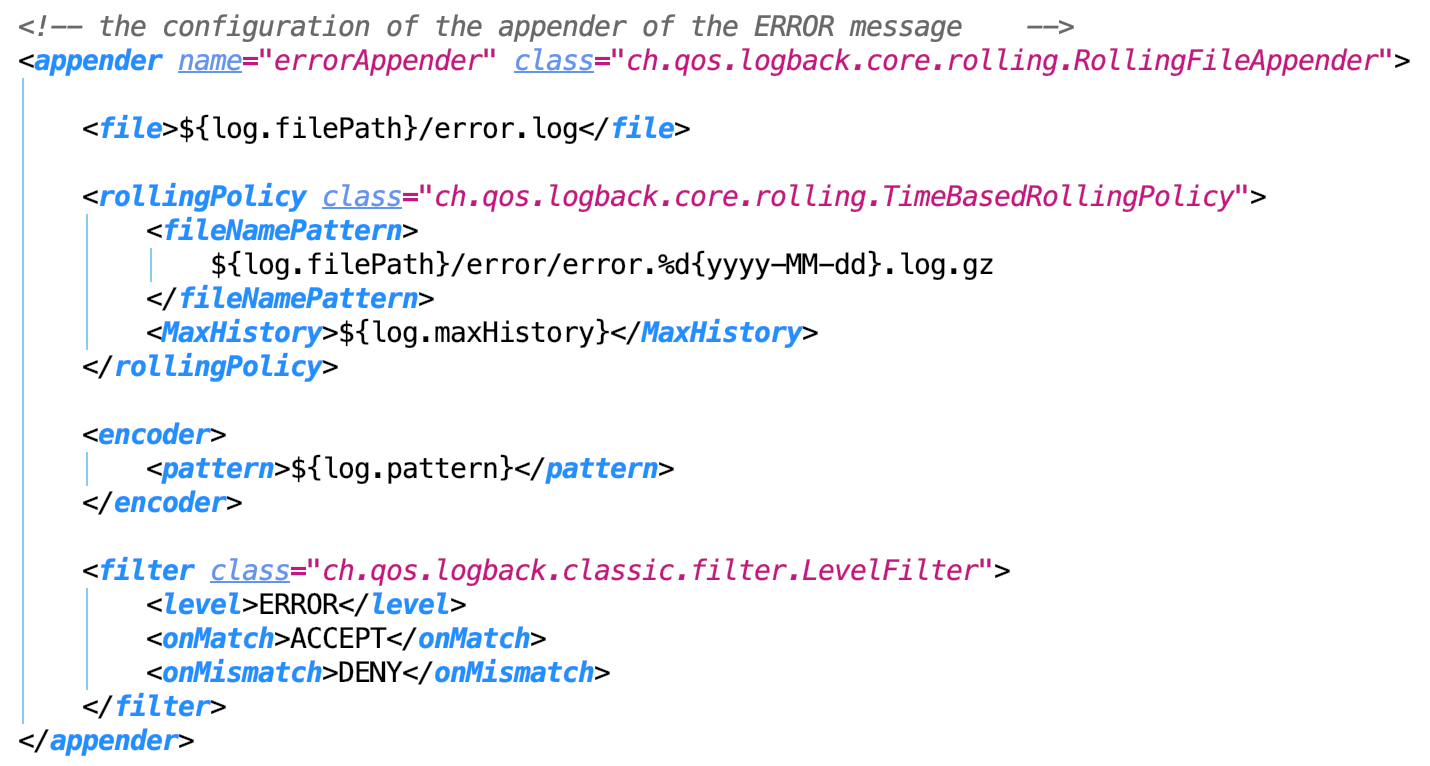
- Defines the logger


Debug: We should change all MaxHistory to maxHistory in the appenders.
Debug: We should change all append-ref to appender-ref in the appenders.
Practice
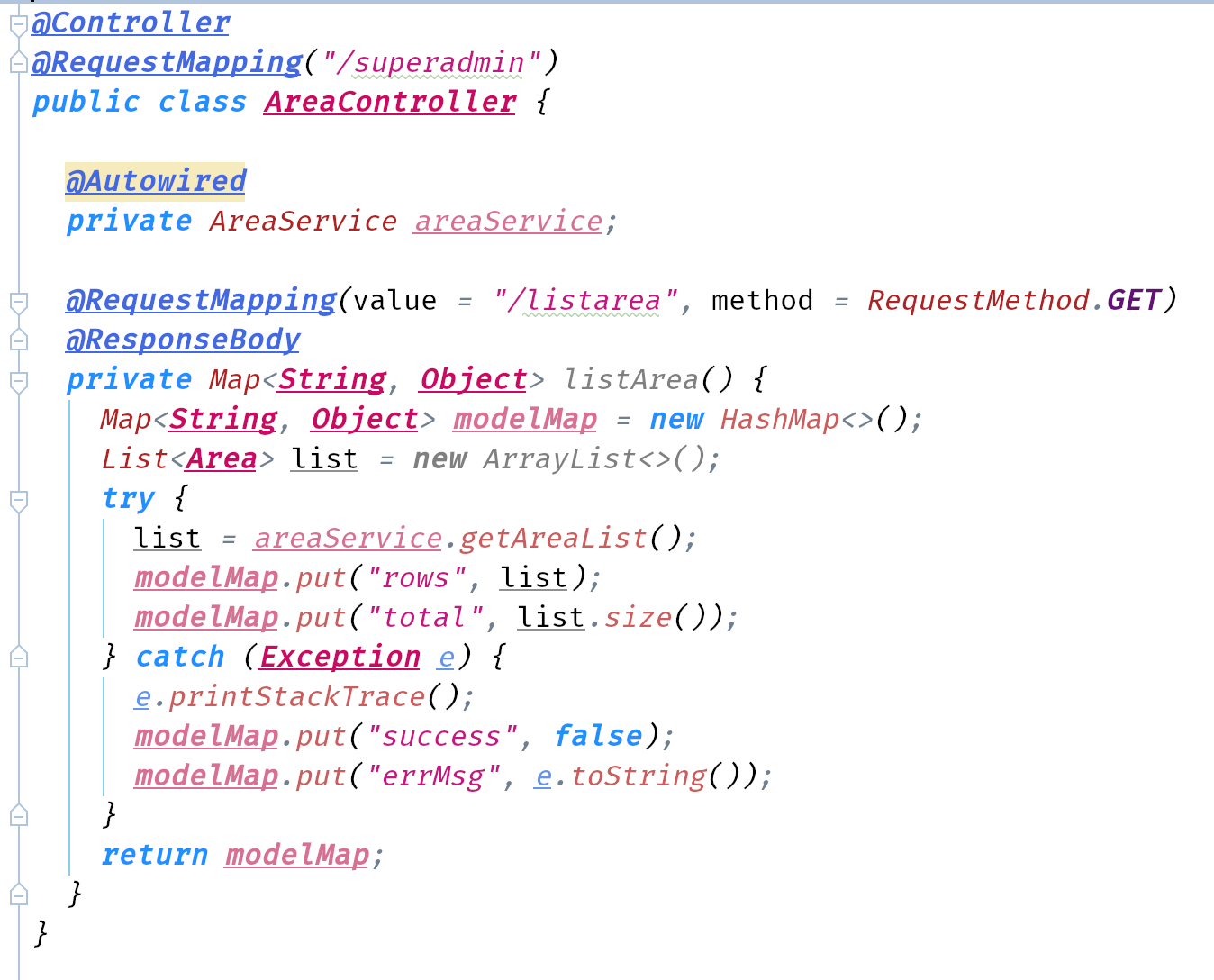
- Initialize a Logger instance in the
AreaController.

- Add some test info statements in the function.
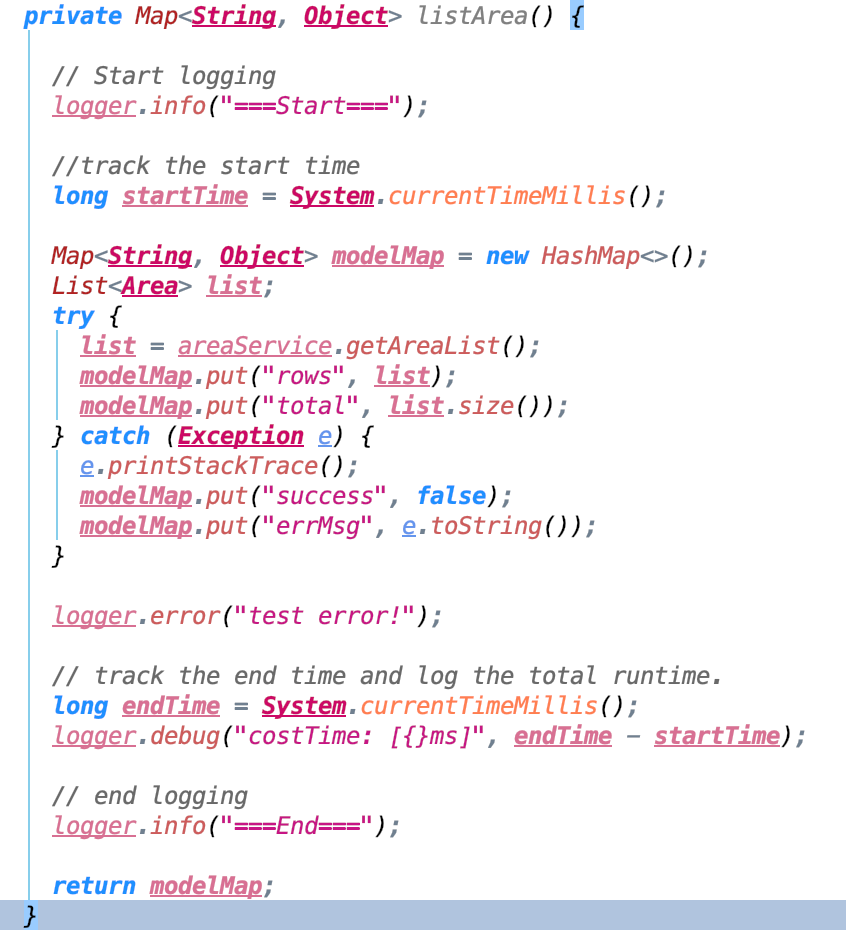
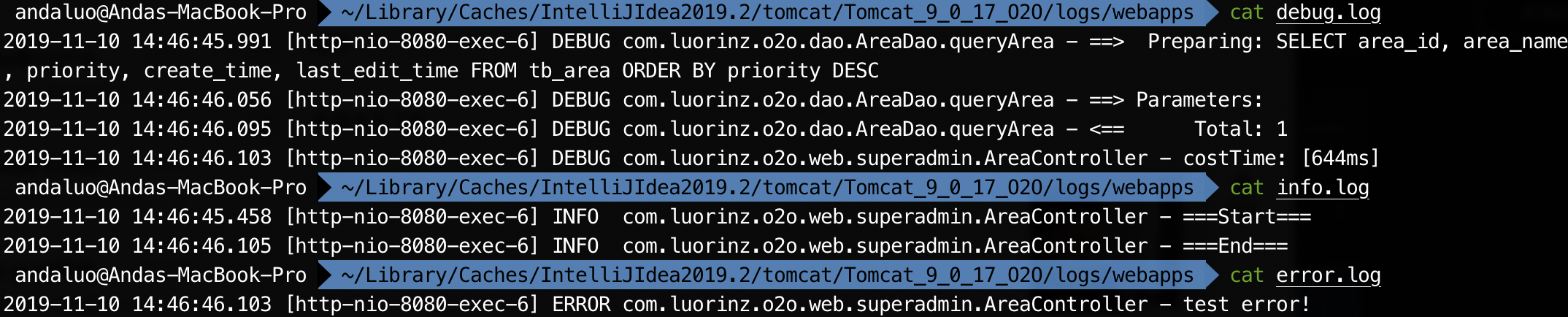
- Check the console and the file.

Here we can search catalina.base to get to the directory of our log files.